Welcome to Research Log #029! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
This week, the team has an update on the Visual Q&A modality. We are working towards a solution where we can stream in the different datasets that we are currently using, rather than store them in memory. This strategy is a bit of a tradeoff between latency and space for training runs of our models. We are still exploring possible strategies. If you want to suggest anything, you can reach out to us through the discord or contribute some code here!
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
The preliminary outline of the Survey appears promising, but there are some issues with LLMs, specifically with their output and narrow focus. Moving forward, we aim to address these concerns and begin the writing process. If you want to join the conversation, reach out in discord!
Pulse of AI
This week some really exciting things happened, here are some highlights: a model that is a true any-to-any input and output model, Google is going back to open source and it is dominating the public leaderboards for their weight category, and a new model that basically can generate other models using the same method as the way that Stable Diffusion and Midjourney work.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
A collaboration of researchers at the University of Fudan, Multimodal Art Projection Research Community and Shanghai AI Laborator have made AnyGPT, a new any-to-any multi-modal language model. This new model uses a discretized representation of tokens to understand a multitude of inputs like text, human voices, images and music.

AnyGPT is a LLama2 7B model on the backend that has different tokenizers and de-tokenizers for different inputs and outputs. For images, they used SEED tokenizer, for speech they used SpeechTokenize and for music, they employed Encodec. You can think about this architecture as an extension of what ADEPT did for Fuyu.

In Fuyu, the model works by doing a Linear Projection to the images. In the case of AnyGPT they tokenize the inputs to discretize them and expand the vocabulary of the original Llama2 7B demo.

They pre-trained the model on a lot of the most common datasets for different modalities. The image datasets were from LAION mainly, for audio it was MultlLingual Librispeech and for music they used Youtube-Music-1M.
The model is not the best at any of the tasks that they trained it for, but it is remarkable that we have one of the true first any to any LLM models. We are actually training another model that is similar to this one in scope but it uses a tokenizer to process things differently, it is called NEKO. If you are interested in helping to develop it, join the discord!
If you want to read further, the original paper is here. For now, the model is not yet in the public, but the official website is this.
Gemma
Google has finally entered the open source arena with a family of models that outperforms Mistral on 11 out of 14 popular benchmarks. Gemma 2B and 7B are Large Language Models that seem to be true competitors in their space.
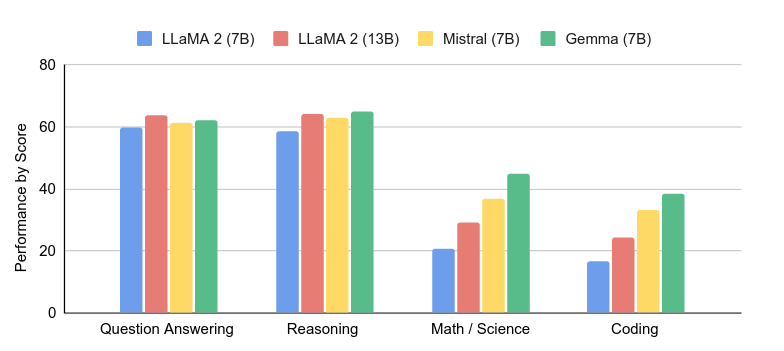
The Gemma 7B model scores consistently better in Question Answering, Reasoning, Math/Science and Coding.
The core architecture of Gemma is the Decoder Transformer but it has some nice new updates. First, they added Multi-Query Attention, RoPe embeddings, a GeGLU activation function and finally Normalizer Location. This model was trained on batches of 8k tokens with Google in house AI chips called TPUv5e. For the 7B model, using 4096 chips and for the 2B one 512.
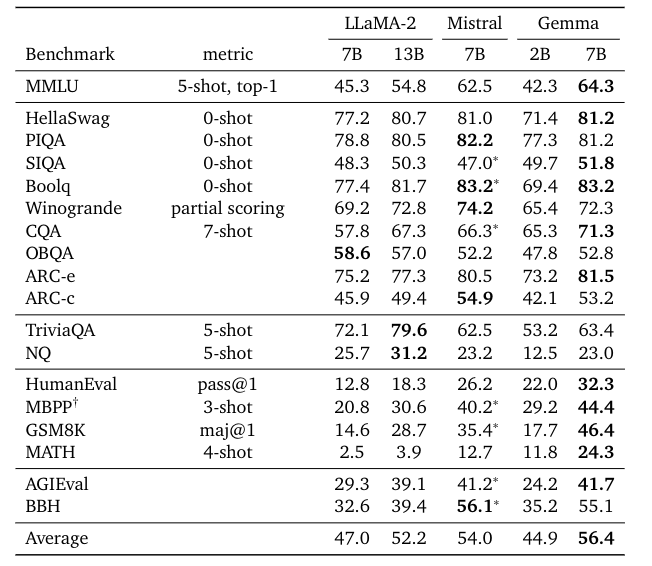
It seems to be a pretty standard release. The main takeaway is that it is the first time in a long while that Google has decided to take the open source route for an AI model. The code is open source and can be found here. The model weights are available in hugging face here and if you want to read further, the technical report is here.
Neural Network Diffusion
Do you think that a Neural Network could be good at predicting other neural networks weights? The answer to this question is yes. Diffusion models are normally used to generate images or videos but now researchers from the University of Singapore, Berkeley and Meta have demonstrated that these models are possible and they are different enough to show that the weights are not simply memorized by the network.
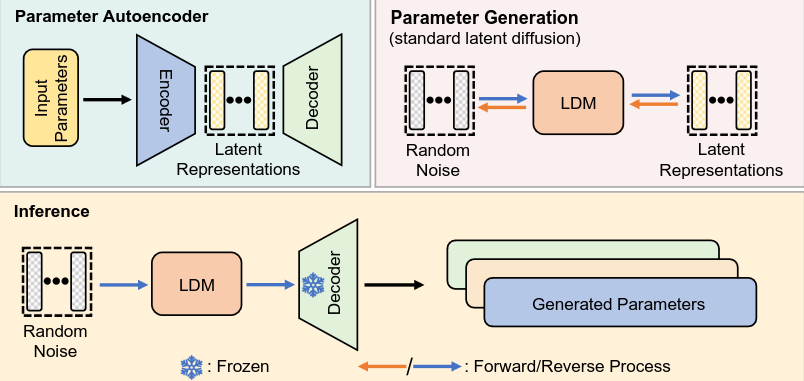
The neural network maker called p-diff is based on “an autoencoder and a standard latent diffusion model to learn the distribution of high-performing parameters”. They train the autoencoder “to extract the latent representations for these parameters”. Then, “ leverage a standard latent diffusion model to synthesize latent representations from random noise. Finally, the synthesized latent representations are passed through the trained autoencoder’s decoder to yield new high-performing model parameters.”

The models produced by the diffusion process sometimes exceed the original training or are near that range.
It could be easy to think that these models are just memorizing the weights, but they have added an entire section of why it is not the case. They evaluated the predictions of original models and calculated the Intersection over the Union (IoU) of the answers.
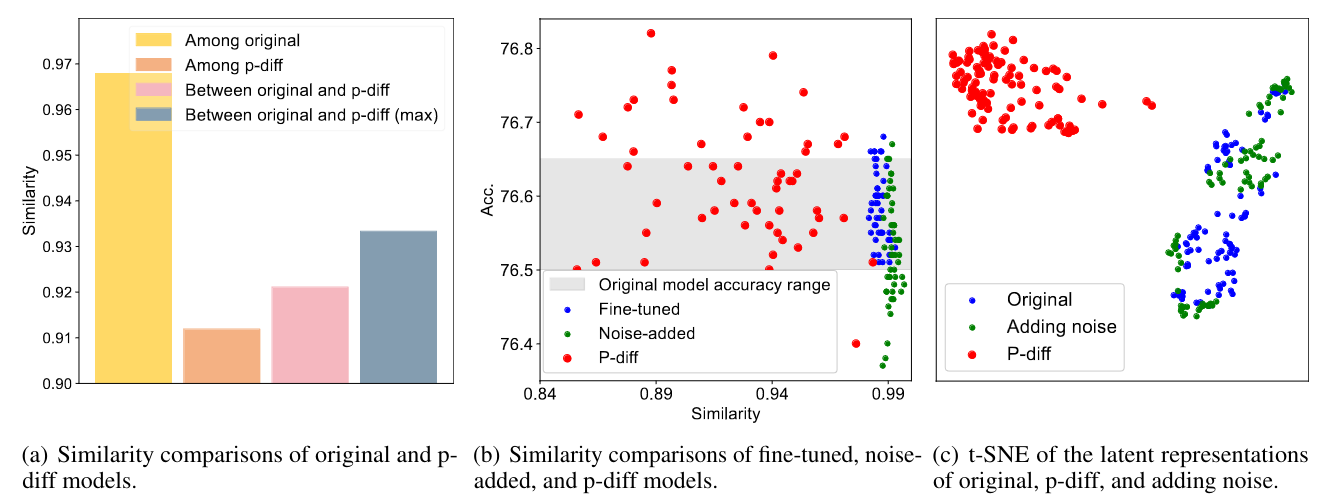
The answer is that the normally trained models and the p-diff models are really far apart. They do not seem to have a lot similar to the original weights.
This is really exciting work! It is obviously early days. But I love the idea that someday we might be able to generate Large Language model weights by prompting a diffusion model. If you want to read further, the paper is here.
If you want to read more, the release page is here and the code is open source and can be found here.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!