Welcome to Research Log #037! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
The team is currently focusing on implementing the usage of Nucleus sampling to mitigate some perplexity issues we have been having. Besides this, we have been working on integrating another Visual Transformer to the NEKO project so that it is easier to use for the VQA and Captions task modality. If you would like to contribute, the github is here.
MultiNet
MultiNet is creating an omni-modal pre-training corpus to train NEKO and Benchmark other MultiModal Models or Omni-Modal Models.
We implemented a framework so that the pre-training corpus tasks for Language, Captions and VQA can be generated using config files. These config files are simple configs where you define what you want from different datasets and you finally merge them so that you can get a single unified API to train MultiModal models. If you would like to contribute to this project, we are searching for contributors, you can hop on the MultiNet channel on the discord or you can open a pull request on Github in this repo.
Pulse of AI
KAN: Kolmogorov–Arnold Networks

One of the fundamental building blocks of basically all neural networks are Multi Layer Perceptrons (MLPs) where you have a model that has fixed activation functions and learnable weights on the edges. This model is incredibly simple and has moved the entire field of AI forward. But, they have their shortcomings. They are not really interpretable and tend to saturate really fast, so researchers at MIT, CalTech, NEU and the NSF have shown a promising alternative, the Kolmogorov-Arnold Networks (KANs).
From the paper: “while MLPs place fixed activation functions on nodes (“neurons”), KANs place learnable activation functions on edges (“weights”)”. These parameters are incredibly efficient, and up to 100 times more accurate compared to MLPs.
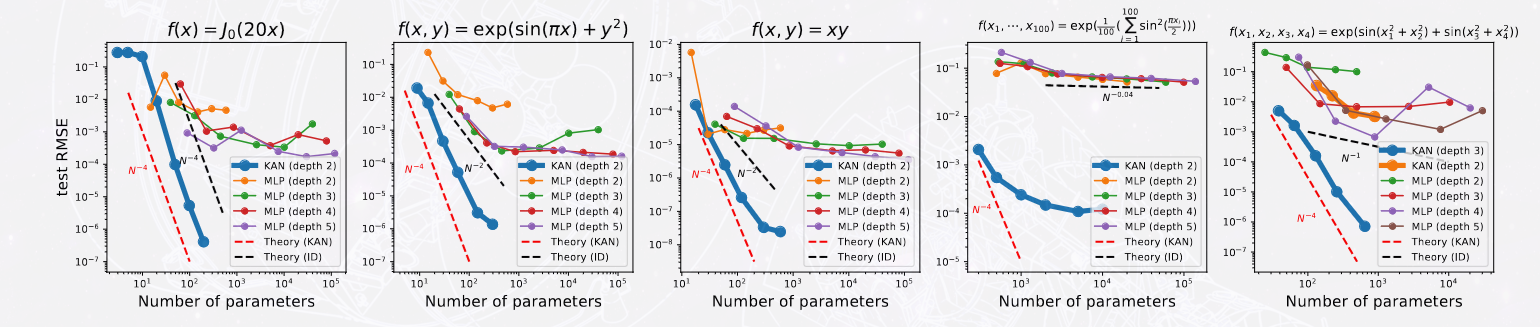
In Figure 2 we can see that the models are not saturated and can learn incredibly well. They keep up in most cases and far outperform the MLPs theoretical and real performance. Especially in the fourth graph, where MLPs are simply flat.
I genuinely believe that if these models genuinely reflect downstream performance, we are going to get adoption of KANs incredibly fast. Now that we are in an AI race of breakneck speed, the edge of using a new fundamental block that is more efficient, interpretable and better more performant it is going to simply swoop the space.
If you want to read the paper, it is on arxiv here. I really recommend it, although the introduction and first section are more than enough to understand it (it’s a 48 page paper after all).
Vibe-Eval
As of recently, most of the benchmarks seem to have the problem of being saturated at the top. Most models seem to easily cross the 80% mark or even more and it is starting to be a genuine problem to differentiate the models that are good from the models that are trained partially on evaluations. The people from Reka just released a benchmark to mitigate this problem. Vibe-Eval is a new multimodal benchmark that aims to evaluate these models fairly (and has the best name possible).

All of the prompts are hand crafted and all of the best models in the world are still failing more than 50% of the difficult set of questions in the benchmark.
I really want this benchmark to succeed. Because we have been going through a drought of good and hard benchmarks. If you want to read the paper, it is here or the release blog post here.
ICLR is happening next week, so we are most likely going to go a bit deeper on some of the papers happening there. That’s it for this week, see you next week!
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!