Welcome to Research Log #024! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
- Datasets: Last week, we covered the proposal of Version 0 of the training dataset for the Vision + Language modality. However, we also need a smaller subset of this dataset to use for test runs, so this week we have proposed a smaller version. More can be read here.
- Control: We are trying to improve the control modality performance of Neko by training on more control datasets. As such, we are currently expanding the control modality team. If you are interested in joining this effort, hop on the discord!
Agent Forge
The AgentForge Project aims to build models, tools, and frameworks that allow anyone to build much more powerful AI agents capable of using tools and interacting with the digital and physical worlds.
This week, the AF team has been reviewing several items like: delving deeper into OS Action Models, learning the current status in Tool Use Models, and cleaning up the project roadmap for the year. Action Models and Tool Use Models refer to models which engage with APIs or other tool interfaces to accomplish tasks. AF team member Thomas, is leading the actual composition of the agent survey draft based on the literature review we have been working on for the last couple of months. We are starting to have a mature enough base that we can hopefully look forward to publishing something soon!
Pulse of AI
There have been some exciting advancements this week!
Scalable Pre-training of Large Autoregressive Image Models
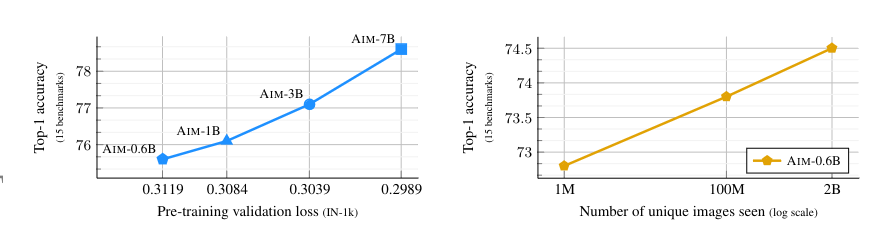
Figure 1: Graphs of scaling laws for the AIM models. Source: paper.
Apple has dropped a new paper which introduced a Large Vision Model, known as AIM. AIM is interesting for two key reasons. 1) Scaling laws seem to apply to this architecture and 2) the value that you get from them on training is a predictor of their performance on new images.
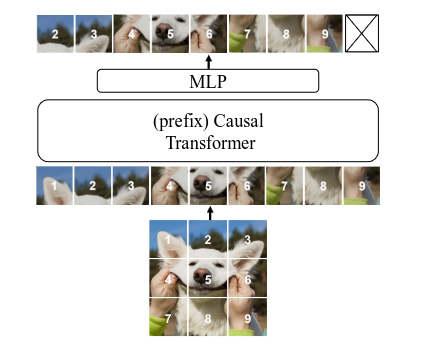
Figure 2: Graphic of the AIM Transformers and how they work. Source: paper.
The Autoregressive Image Models (AIM) models are trained in a similar style to LLMs. The images are segmented into patches. The Causal Transformer is fed the pieces and tries to predict the following slice. Aside from that, they try to minimize the negative log-likelihood, as is common in a lot of pretraining strategies.
If you are interested in reading more, the paper is here. Apple released the weights here, this represents a positive step for Open Source ML!
MAGNeT: Masked Audio Generation using Non-autoregressive Transformer
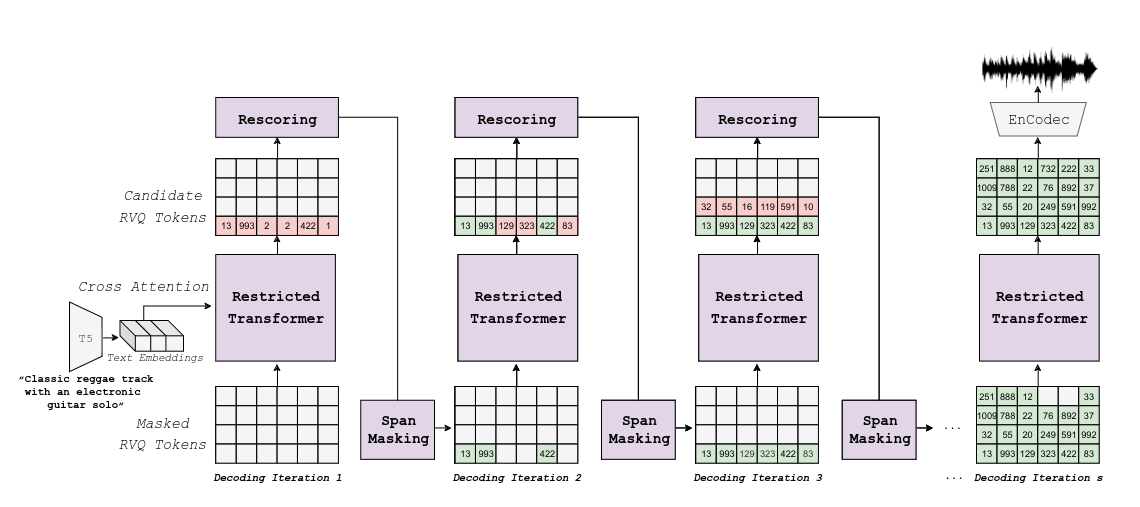
Figure 3: MAGNeT inference. Source: MAGNeT paper.
Researchers from Meta, Kyutai and Jerusalem University have created an Open source model that can generate music based on a prompt.
The inference works by passing text embeddings to a Restricted Transformer. This transformer outputs candidate tokens. Then another pre-trained model scores each of the tokens and only the ones that the pretrained model thinks are best are left behind. Now, with the outputs of this decoding they input it back to the Restricted Transformer and the process described before repeats until you have the full length audio clip in token form. Finally EnCodec translates from tokens to a soundwave.
This approach beats state of the art and the coolest part is that you can go and play with it now! There are model weights on huggingface and the paper for further reading is here.
Transformers are Multi-State RNNs:
Here’s a paper to blow your mind!. Researchers at Meta/Jerusalem University were capable of demonstrating that the architecture we know and love, the decoder-only Transformers, are simply Multi-State RNNs under the hood.
They define a new variant for Recurrent Neural Networks named Multi-State RNNs. This new RNN has a matrix instead of a vector for state. In this case RNNs would be a special case where the size of the state is equal only to a vector of size n=1 and not a matrix of size n x m.
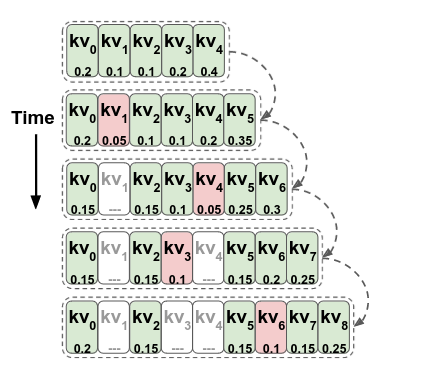
Figure 4: The image of the TOVA policy. Source: paper.
They introduced a policy called TOVA (Token Omission Via Attention), a simple Policy where “At each decoding step, we consider the softmax-normalized attention scores from the current query to all the tokens currently in the multi-state, plus the current token. The token with the lowest score is dropped”.
If you want to dive even deeper and look at the code for TOVA it is here and for a further reading of the paper this is the link.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!