Research Log #030
Welcome to Research Log #030! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
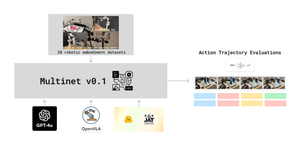
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
The Version-0 of the benchmark (pre-training corpus) we want to propose is done, previously discussed in Research Log #023. That is why this week we collected a list of state of the art multimodal open source models we could find and we are going to try them to see how well they perform on this benchmark. If you want to discuss the list, hop on the discord and talk about it on the NEKO channel!
Here is the list of models we are going to benchmark:
Pulse of AI
This week, there are a few developments that caught our eye: a new model that can generate video games just from a prompt, Mistral and Anthropic released a new model capable of competing with GPT-4, and a new model that shows promise as a personal robot assistant.
Genie
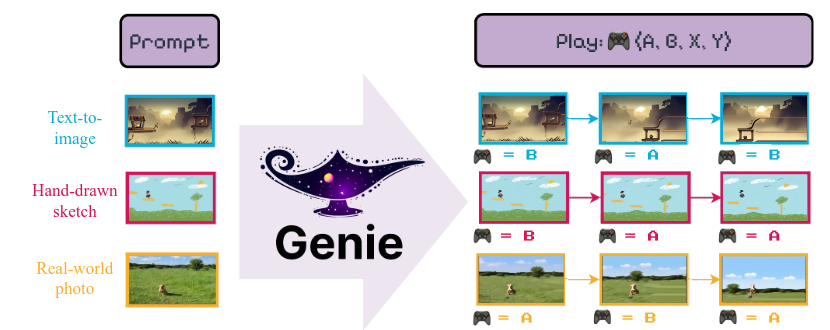
Would you like to design a video game on paper, take a picture and a prompt to an AI model and generate a fully fledged video game? Researchers at Google DeepMind have done just that. They have introduced a new model called Genie.
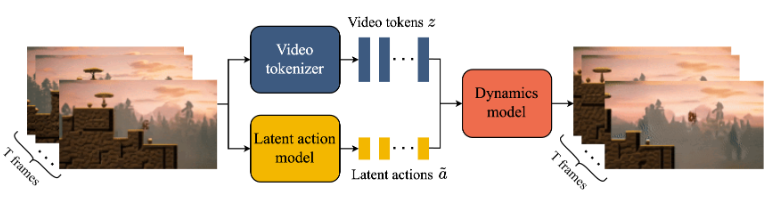
“Genie is a generative interactive environment trained from video-only data.” The way they trained this model was by tokenizing the video and trying to predict in a latent space the actions that it would take. It is similar to the next token prediction in LLMs, but in this case it is just for the next action.
The best part about this method is that you only need video to train. The actions are inferred so automatically any video is usable for you as a training video. You do not need to label anything.
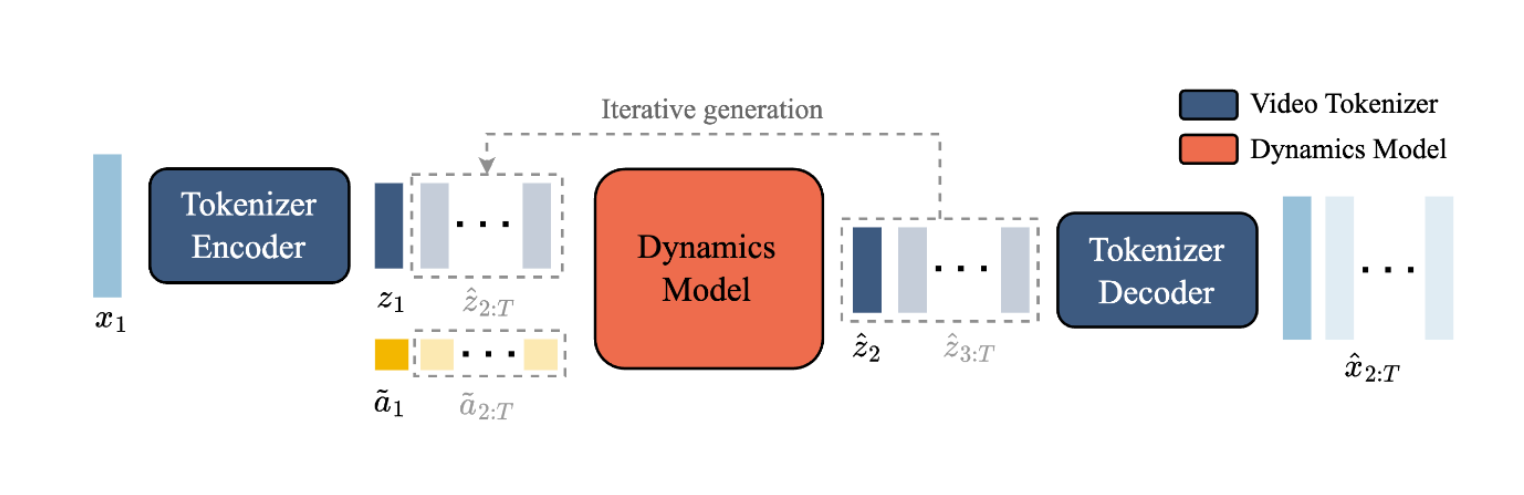
For the inference pipeline what happens is that the prompt made by the user is tokenized and combined with the actions the user is inputting. The inputs are passed to the Dynamics Model which generates a response based on the inputs. Finally the tokens are decoded to images via a decoder.
The video game training is interesting, but there is another model that they talk about in the paper that also seems promising. This Genie model is trained to do simulations of robotic bodies using the same pipeline. By using the R1 dataset, they were capable of training a model that can simulate robotics with just video of how the robots work and their respective inputs.
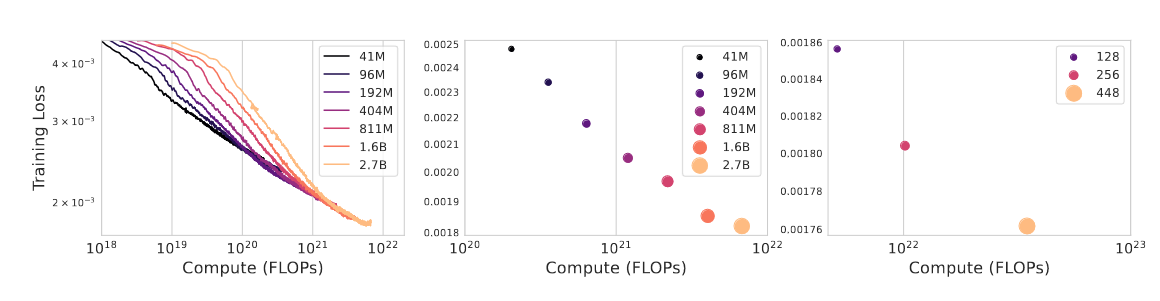
The scaling laws work as expected with more compute and bigger models equaling better loss. We are in the era of LLMs so a 2.7B model seems tiny, but it still needs a massive amount of training budget for the average person.
If you would like to delve deeper, the paper is here. And the released blog post has some super cool technical demos here.
Claude-3
Anthropic, the AI research lab, released a new family of models capable of beating GPT-4. It is interesting how more and more companies seem to beat or be on par with the state of the art after almost one year of the release of the best model in the market.
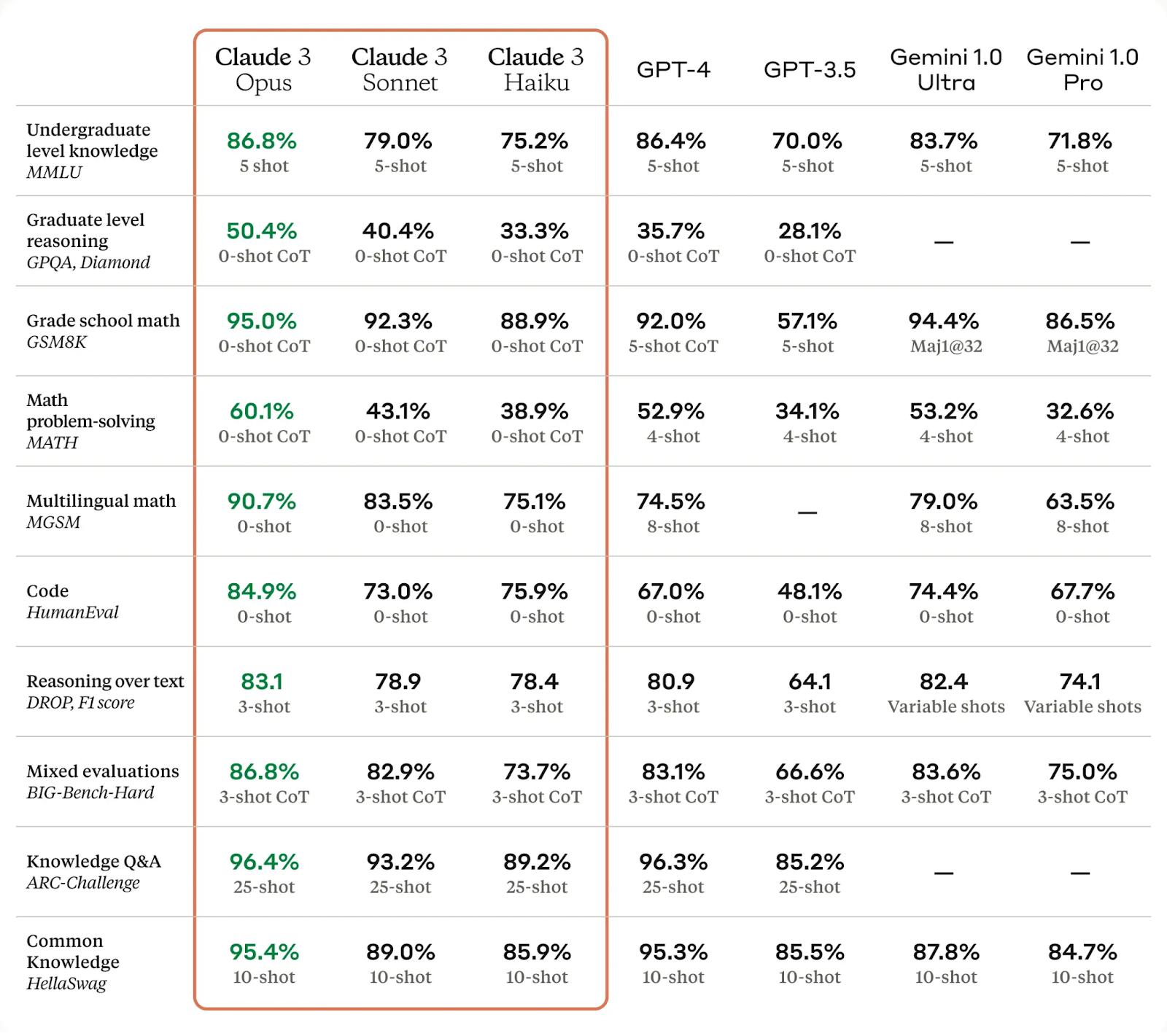
There are three different sizes: Haiku, Sonnet and Opus. Each model is more capable than GPT-3.5. All of the models are capable of accepting images as inputs.

It seems that the state of the art for Image comprehension is still in Google’s hands, with the Gemini Ultra models.
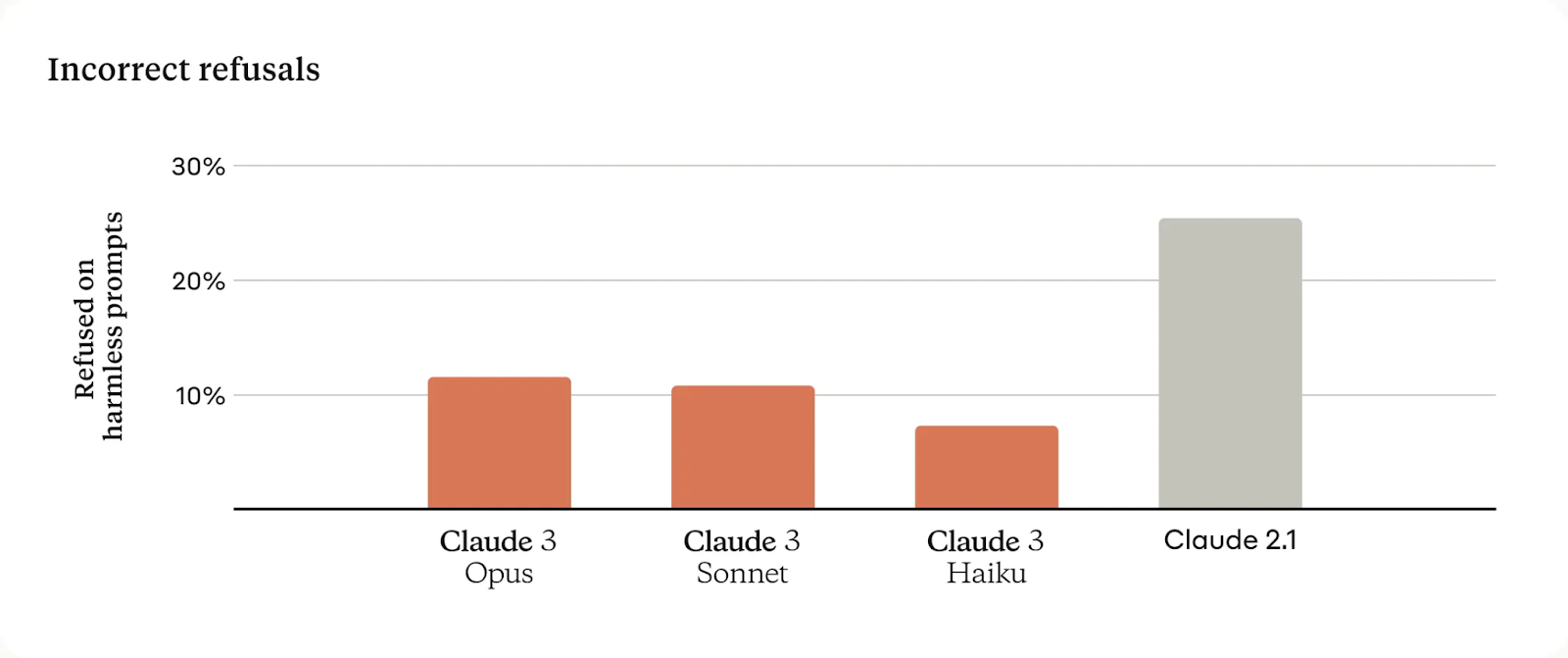
With this release, they have fixed a lot of the “refuse to answer” behavior of Claude-2. Anecdotally, I can say that the experience with the new models is better and the large context window is amazing to process documents.
If you want to read more, the release blog post is here and the chat interface is at claude.ai here.
Mistral Large
Mistral, the French AI company has released two new models and a new chat architecture. The new model called “Au Large” is a proprietary model that is capable of almost beating stuff like OpenAIs GPT-4 and surpassed the first version of Gemini.
With the release of this new model, they created a new chat platform available here. Called “Le chat” (the meme won lol) and the logo is just amazing.
Another interesting thing is that in the chat platform they released a bit of a more mysterious version called “Next”. The cool part about “Next” is the conciseness of it. This LLM is specifically tuned to get to the point. With models being consistently good, a great differentiator is to not be verbose.
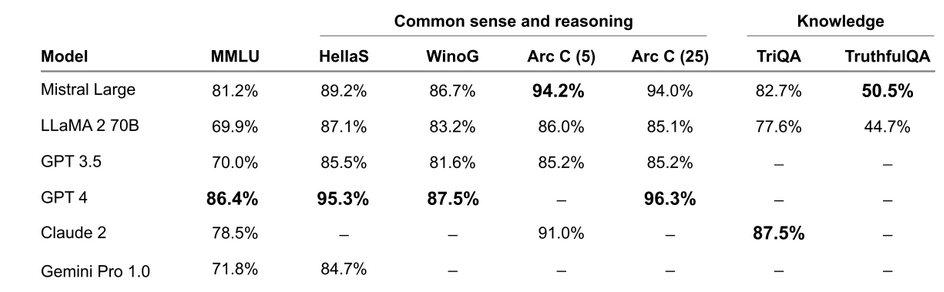
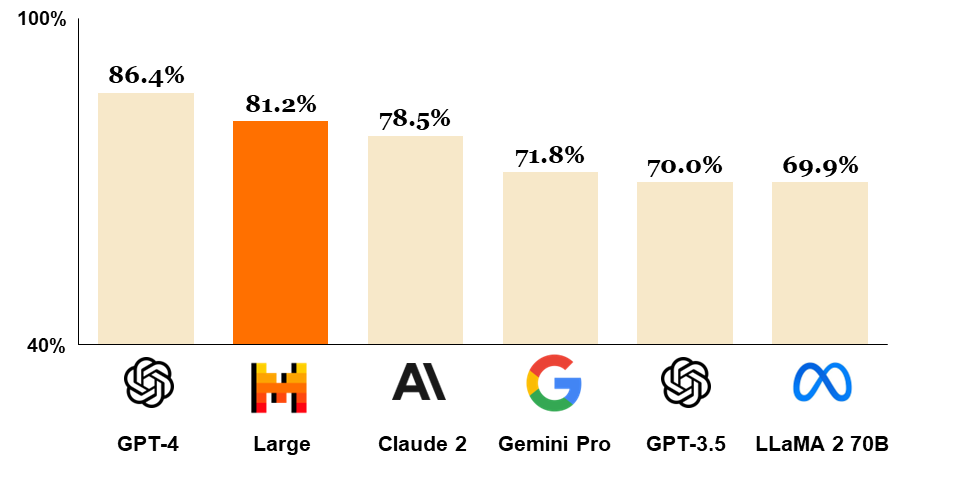
Mistral Large is a pretty good model overall, it sometimes even surpasses SOTA in some areas.
The twist that nobody was expecting is that they partnered with Microsoft and their API is only accessible through Azure. Nobody was expecting Mistral to partner with the father of their biggest competitor. Most likely Microsoft is diversifying their AI portfolio because OpenAI can sometimes bring problems with their governing structure.
If you would like to test the Next or Large models, check it out on le chat here. And if you would like to read the release blog post, it is here.
OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics

Integrating robotics with the real world can be difficult, but it seems that we are reaching a point where we could get a robotic assistant in the near term future. Researchers at New York University and META were capable of integrating a lot of different AI models and creating a new robot called OK-ROBOT that is capable of making pick and drop actions in the real world without the need of specific training.
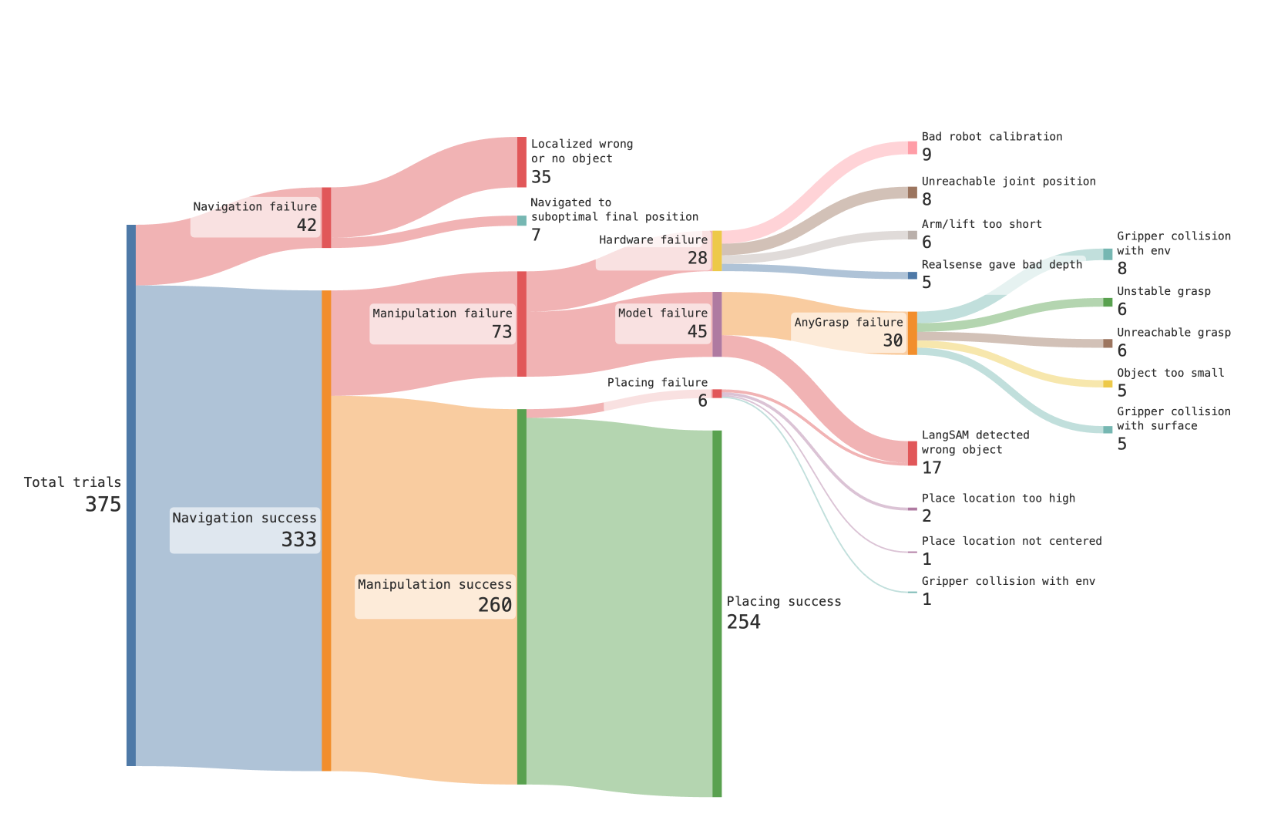
The experimental results seem promising, succeeding in 82% of the trials when the house is ordered. When the houses are more disorganized, the model drops to succeeding about 58.5% of the time, which is not that impressive but still solid.
If you would like to read more about this robot, the paper is here. They open sourced a lot of what they did! So you can read the code here.
That’s it for this week's Research Log!
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!