Welcome to Research Log #039! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
Manifold Updates
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
The NEKO team has been working on merging the fix from two weeks ago, mentioned in Research Log 38, for the text modality that improved our perplexity score on the text modality. We are also currently working on getting the vision modality that we are using to an improved state. If you would like to dive deeper into the code of NEKO, you can check it out at the github repo!
MultiNet
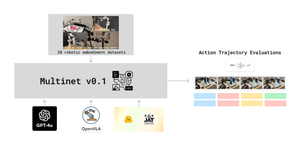
MultiNet is creating an omni-modal pre-training corpus to train NEKO and Benchmark other MultiModal Models or Omni-Modal Models.
The MultiNet team has been working on the control part of the datasets for MultiNet. We have decided that the best course of action for the control datasets is to translate all of them into a common format known as RLDS.
We were capable of translating the JAT dataset into RLDS and we are focusing on the port of two different datasets right now: the first one is a locomotion dataset called V-D4RL and the second one is for a “videogame” and it is called Procgen.
If you would like to help in this translation process or if you are interested in training an Offline-RL model, please check out the open source repo in here or chat with us in the discord channel for MultiNet!
Pulse of AI
We are diving deep into the anatomy of Claude Sonnet because LLMs have stopped being black boxes and we can now understand their internals. A new model and training regime from Meta was introduced that is capable of having images and text as input and as output too! One of the most exciting advancements happened this week for the Transformer architecture, it is now capable of doing math and generalizing past the training set. And finally a new training regime that makes CLIP models better for long Image-Text sequences is getting state of the art results.
Golden Gate Claude
For 24 hours the past week, you could talk to a Claude model that was obsessed with the Golden Gate. This time it wasn’t a fine tune or a prompt that made the model obsessed with the bridge but an understanding of the underlying way that Claude thinks and views the world.
So how did it work? Large Language Model features were thought to be black boxes, but there was a method to interpret them by training another smaller model called a Sparse Autoencoder (SAE). Anthropic already had started doing research in this direction late last year. They dug into the math and didn't find any red flags saying it was a no-go to scale things up. So, they decided to put their hypothesis to the test and see if SAEs could handle the bigger parameter size. They trained a model on Sonnets middle layers to generate features that can be interpretable by any human. The model was trained specifically to try to mimic the “middle layers” of Sonnet, so that you could “extract” and interpret what the LLM is thinking.

These SAE models can generate features that then can be passed to a dimensional reduction algorithm like UMAP so that we can understand in a simple 2D map what is happening behind how an LLM really thinks.
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Mixing image generation and text generation sounds like a crazy Chimeric model but researchers from Meta have managed to make a new model capable of this that is better at text than Llama-2 and is on par with Mixtral 8x7B and Gemini-Pro.
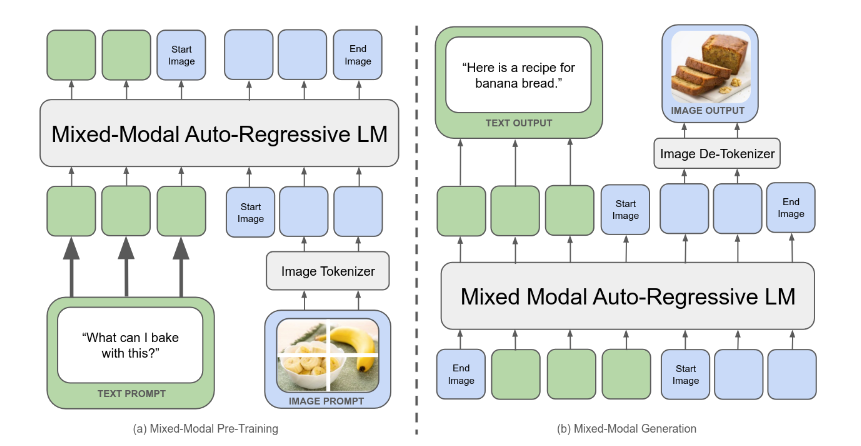
The underlying architecture follows Llama-2 but it has some differences to be capable of stabilizing the training for the generation of Image tokens because multiple modalities tend to “compete” and normally diverge from token generation. They found out that the softmax operation was lending them some trouble at mid to late stages of the training so they ended up normalizing the queries and keys, this method is called QK-Norm.
A cool part about these papers from Meta is that they disclose the amount of GPUs to train both of the Chameleon models. For example, Chameleon-34B was trained for 58 days or a cumulative of 4282407 GPU hours over a 3072 GPU cluster.
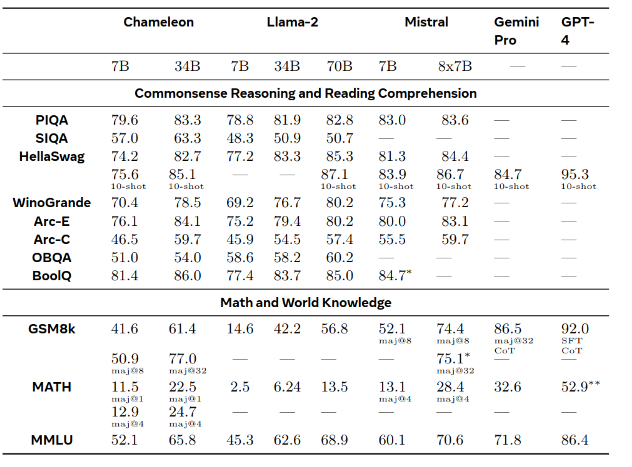
Although it is not the best model for text, it is pretty obvious that for its size, it is doing a lot.

As for Visual benchmarks, it loses against the closed source models but it gets incredibly close to the open source ones even if they are almost three times its size.
Check out this paper if you are interested in multimodal research. Although the weights are not open source, a lot of the underlying decisions are described in the paper and it is a deep dive that is worth your time at least skimming. If you want to read it, you can find it here.
Transformers Can Do Arithmetic with the Right Embeddings
Everyone knows that Transformers are really bad at math, until now. Researchers have found a way to make them good and generalizable.
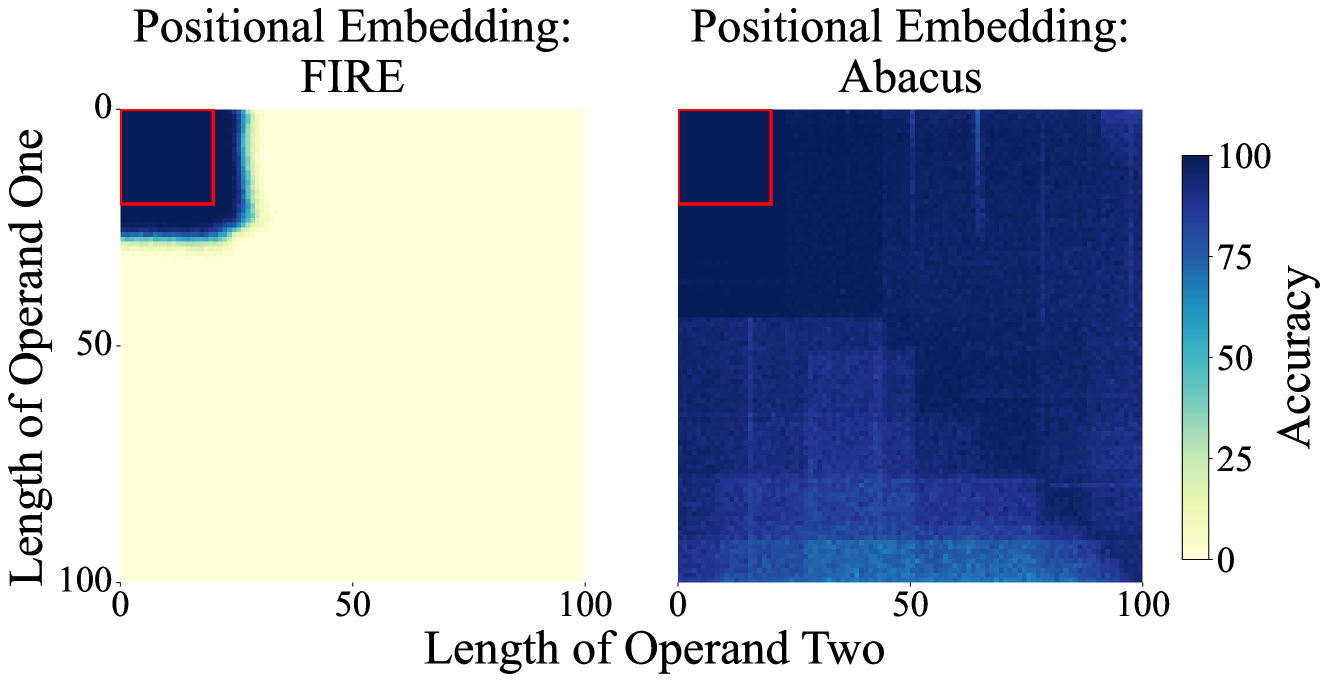

The way that they did this is by creating a new positional embedding called Abacus embeddings, these positional embeddings are just trainable parameters specifically for numerical tokens. The idea behind this is that the problem that Transformers have is that they can’t keep track of the position of the numbers, but with the new method their performance in addition tasks improves by 6x.
The transformer models in this case were trained to do addition but the same method is generalizable to be used for multiplication and sorting of numbers. The model can sort to up to 10 digits. I know this does not sound great but prompt ChatGPT to sort some numbers to get an idea of how bad SOTA transformers are at this.
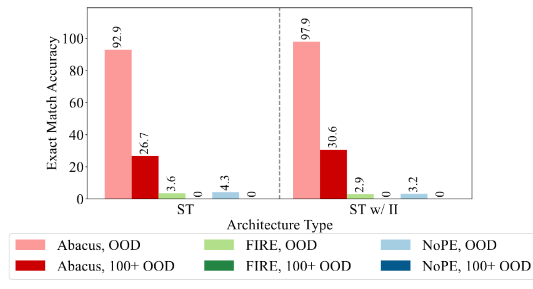
It seems that specifically for addition, you can get near to perfect results with this method and it seems that it is a solid step for using transformers as a calculator.
If you would like to go further with your research, the original paper is here.
Jina CLIP
CLIP models normally have this problem of not being really good at long sentences because they were mainly trained on the alt text of images. So the people from Jina created a model that is capable of understanding text better and creating better embeddings.
The underlying architecture of JinaCLIP uses a variant of the BERT model named JinaBERT that makes BERT support longer text, as for the image encoder, EVA02 was the pre-training starting point.

The way that they got such incredible results was by optimizing for two different tasks, the first one was text-image pairs and text-text pairs. Leading to a model capable of generating embeddings as good as EVA-CLIP for image text pairs and state of the art traditional embeddings tasks. The entire pipeline consisted of three different stages:
- Learning images and text + short text-text pairs.
- Optimize longer synthetic image captions + text-text pairs.
- Long captions + hard negatives to make the model discard irrelevant text.
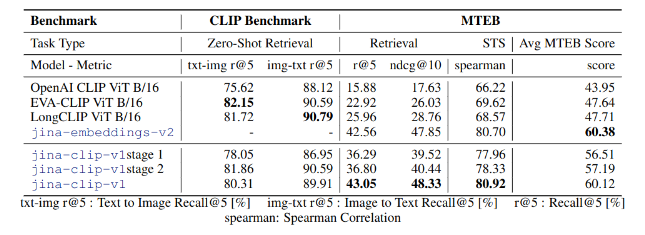
Overall, the pipeline they present for embeddings seems good for the results they are getting. The results for long text are really good but still not SOTA which is a tradeoff for the best results in image embeddings. The results are super close to each other and honestly, I don’t think there is enough difference between each result. I think we need better benchmarks for this.
This is the first time Jina has created an AI model capable of generating image embeddings, for sure v2 is going to fine tune their training corpus and beat SOTA on the CLIP benchmark too.
If you would like to read the original paper, it is only a four page read. You can find it right here, and they also released the open source weights right here.
Thanks for reading this week's research log! See you until next time.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!