Welcome to Research Log #026! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
- This week, we’ve primarily been focused on debugging & improving some aspects of the VQA performance prior to a merge to the master version of the model, in preparation for a larger training run!
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
- We’ve made some progress in compiling V0 of our survey, found here.
- We’re also exploring agent definitions, and compiling work into the review material tracker.
Tool Use Models
The Tool Use Model Project is an effort to build an open source large multimodal model capable of using digital tools. We’re starting with exploring the ability to use APIs. Get involved with the project on discord!
- We’re currently in the middle of surveying available action models (turns out there are very few) and related datasets. We’ve compiled some example datasets here.
Pulse of AI
There have been some exciting advancements this week. A completely open source Model has entered the arena, a new text to video model that blows other results out of the water and text to 3d mesh 10x faster than before. Read on for this week's Pulse of AI!
Dolma & OLMo
Dolma and OLMo are a new dataset and state of the art LLM from AllenAI. It is one of the most exciting projects in a while because everything is open source about it. The pretraining data is completely open and for OLMo there are checkpoints every 1000 steps until the end of model training. These are real free and open source models!
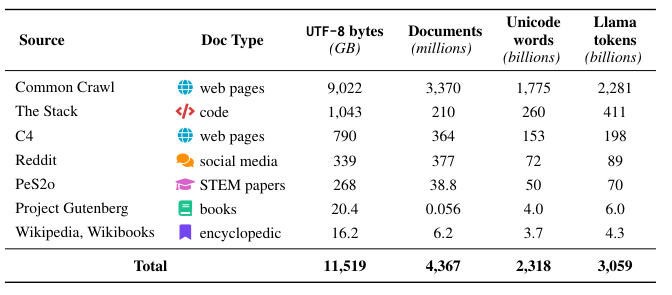
Dolma is a corpus of Three Million Tokens. There are multiple sources for these datasets, they have classics like Common Crawl and C4, passing through Wikipedia and project Gutenberg. Originally, before cleaning, and careful selection there were 200TB of raw text. Dolma was created because there is a need for bigger and more high quality open source datasets. It could be seen as a competitor against C4, Pile and the RedPajama datasets.
OLMo is a family of languages trained on the Dolma dataset. They used a decoder only transformer and have released two models with a third one awaiting release. The models are 1B and 7B parameters with a 65B model still training.
OLMo and Dolma are completely open source, even the tooling can be downloaded. If you want to read more about it, you can check the Dolma paper here and the OLMo paper here
Lumiere

A new text-to-video diffusion model that basically blows the competition by Google out of the water. This new model is more realistic and can be used for stylized generation, conditional generation, image to video, inpainting and cinemagraphs.
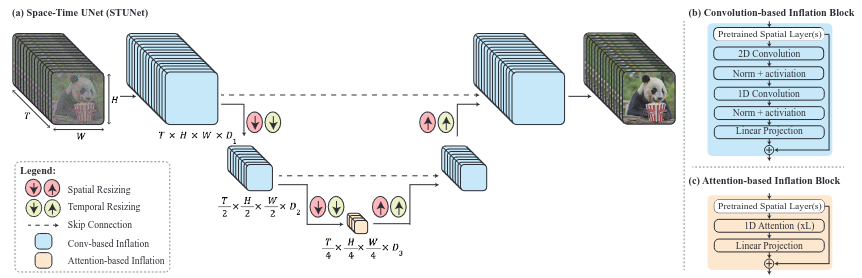
The model is based on a normal text to image U-Net that they “inflate” into a space-time U-net. Finally, the crux of the model is an Attention-based Inflation block and the rest of the downsample and upsample blocks are Convolution based. They trained the model with 30M videos along with their text captions.
If you want to read more, you can check out the webpage or their paper.
AToM: Amortized Text-to-Mesh using 2D Diffusion

AToM is a new text to 3d object model made by researchers at Snap research and KAUST. The advantages of this new model are that it is roughly 10x faster than before and it has 4x more accuracy than prior state of the art in some datasets.
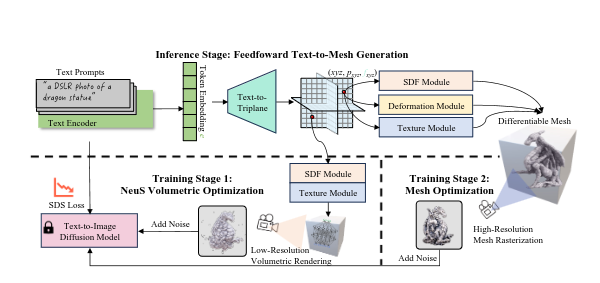
The model has two different pipelines, one for inference and the other one for training. The inference works by encoding the text prompt into a triplane where a 3D network generates the meshes from the triplane features. The training has two stages, the first stage the model trains the 3d generation and the second part has mesh optimization so that the output is more refined.
If you want to read more, the paper is here, and we hope they will eventually open source their weights.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!