Welcome to Research Log #027! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
- Major update to the main NEKO implementation - we’ve merged in stable changes including the addition of Visual Question Answering.
- We’re preparing for more data and a larger data run, and have some exciting dataset updates planned for the coming week!
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
- We’re in first draft writing mode! We’ve managed to start coalescing our broader survey into a single draft to be released as V0 later in the Spring. More on this soon!
Tool Use Models
The Tool Use Model Project is an effort to build an open source large multimodal model capable of using digital tools. We’re starting with exploring the ability to use APIs. Get involved with the project on discord!
- The team is evaluating how different approaches to fine tune LLMs may result in better tool use, and will have some updated project directions and roadmaps out later this week!
Pulse of AI
Some interesting and exciting things happened this week! A new model that can understand Audio in the same vein as Flamingo could also understand Video. A new method to align AI models that is incredibly simple but powerful. And finally a new method to train CLIP models that beat the state of the art. Read on for this week's Pulse of AI!
Audio Flamingo
Flamingo is an interesting architecture that was originally developed by Google in this paper for Video tasks. Now, Audio Flamingo is a new LLM from researchers at NVIDIA that is capable of understanding audio.

The architecture of AudioFlamingo starts with a sliding window feature extractor called ClapCap which takes 7 seconds of audio at a time and translates them into Mel Spectrograms. After grabbing the features they transform it through a module consisting of “3 self-attention layers, with 8 heads and inner dimension 2048 each”. Then, they condition the audio with a gated xattn-dense layer and finally pass this to a decoder only LLM (in this case OPT-IML-MAX-1.3B).
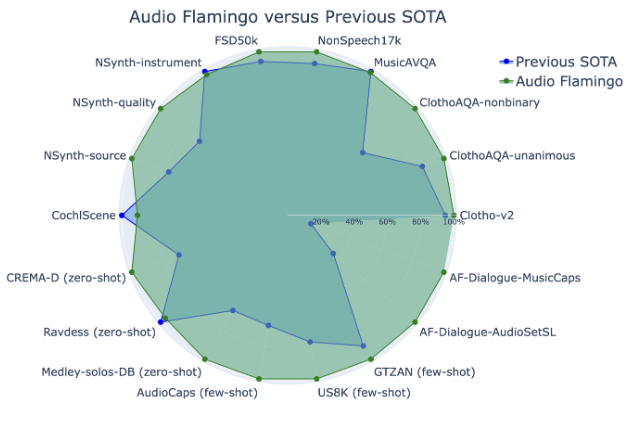
Their new approach basically beats everything from the previous State of the Art and consistently dominates in all of the datasets they tested against.
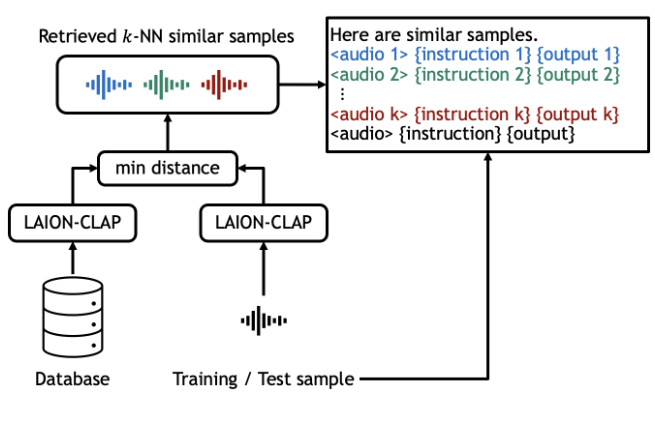
The pipeline that they used to generate the In Context Learning dataset is as interesting as the model itself. They used Retrieval Augmented Generation to grab training and testing samples that seemed similar so that the model could understand more from context. The pipeline they used was to generate embeddings using LAION-CLAP and computing the minimum distance between similar audio samples.
If you want to see some demos of how this model is currently working, checkout their demo page. And if you want to read more, check their paper here.
Direct Language Model Alignment from Online AI Feedback
How do you align an LLM with an LLM? Well, researchers at Google DeepMind have comed up with a solution for this problem that works in an online fashion. The problem with methods like RLHF or DPO is that they work offline, this new method works in real time, constantly updating itself.
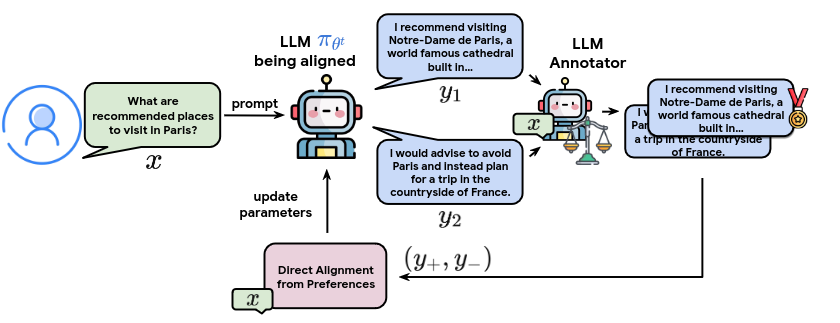
The way that online AI feedback (OAIF) works is that you have two large language models. The model you are aligning and the one that is annotating the answers. What you do is the following, you make the unaligned model produce multiple outputs and then the annotator chooses the best response. The idea is simple and it works!
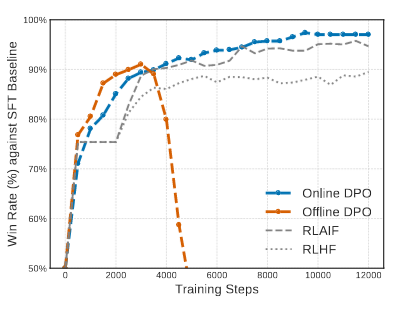
As we can see in Figure 5, the new method works a lot better than RLHF and it is not overfitting like Offline DPO. The problem in this case with Offline DPO is that past a certain threshold it overfits. But Online DPO keeps working properly and getting better over every step.
If you would like to read more about this new online method you can do it here.
EVA-CLIP: Improved Training Techniques for CLIP at Scale
CLIP models are a major part of how most of the diffusion models work. They are the models that mix text with images. The way they do it is by using an image and text encoder . EVA-CLIP is a new suite of models by researchers at baivision that outperform the previous state of the art and are cheaper to train.
The new approach that they used is the following: First, they used a pretrained model called EVA to initialize their image encoder and used OpenCLIP or the original CLIP to initialize their text encoder to stabilize the training. Then, CLIP models normally use gigantic batch sizes; the original model used 32k images per batch. So they used LAMB because it is designed for larger batch sizes. Finally, another trick they implemented was FLIP which consists of “randomly masking out and removing a large portion of image patches during training”. They masked 50% of the images so that they could 2x their batch size.
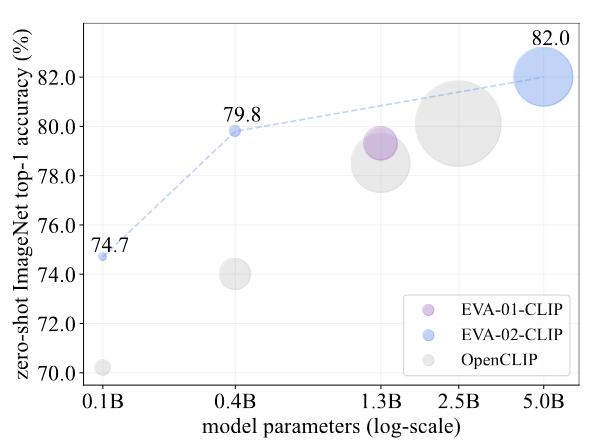
The results of this new way of training show their capabilities for the zero-shot performance in ImageNet. These models are better on average than OpenCLIP or CLIP across multiple benchmarks like ImageNet, ObjectNet and CIFAR.
If you want to read more about how this new way CLIP models are trained or their performance in more benchmarks, the paper is here. The code is open source! So you can check it out if you want to test the models, the code is here and the weights are here.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!