Welcome to Research Log #032! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
We have started a new Github Repository for all of the work involving MultiBench. This is going to be the place for benchmarking and getting results for our pre-training corpus for NEKO. If you would like to collaborate on one of the first multimodal benchmarks and pre-training corpus, the github is here.
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
The team has entered its final sprint as mentioned in Research Log #031, and is working on v0 of the survey paper. Stay tuned for our release of it, and if you are interested in joining any of our agentic research projects, check out our github.
Pulse of AI
This week, the hottest GPU maker in the world made its annual conference and unveiled a GPU that is 2.5x faster than the last one, model merging just got a new method that allows the defeat of models 6x the size, a new method to make AI models think before they speak and finally Elon open sourced one of the biggest AI models in the world.
GTC happened this week

The main conference from NVIDIA named GTC happened this week. They unveiled the new architecture for their chips, it is called Blackwell.

The new BP200 Grace Blackwell Superchip has 40 petaFLOPS of “AI performance”, but in reality it is 2.5x faster than Hopper. Because nobody normally trains using FP4. We are still waiting for more stuff like The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits. It has 20 petaFLOPS of FP8 compute and it has a crazy 7.2TB/s of NVLink bandwidth.

The GB200 NVL72 is the new server specifically designed for “AI compute”. The capacity of this beast is of 1.4 exaFLOPS for “AI performance”.

If you were Microsoft, Meta or Google, maybe you could buy a full Data Center with 32,000 of these GPUs and have a total capacity of 645 exaFLOPS.
Every time I see one of these conferences I tend to think that they talk about alien technology because I am not going to own one of the datacenters any time soon. However, hopefully this development will make normal GPUs cheaper. If you would like to watch the entire keynote for NVIDIA GTC, it can be found here.
Evolutionary Optimization of Model Merging Recipes

Sakana AI is the research lab of Lilion Jones, one of the original authors of the "Attention Is All You Need" paper. The other co-founder and co-author David Ha with other three researchers recently published a new methodology centering around Evolutionary Algorithms. They demonstrated a novel approach to generating new models without training, using the classical technique of merging the best features of each model but with a twist, employing Evolutionary Algorithms. Through this new method, they released four new AI models, three of which are large language models (LLMs) and the fourth being a visual language model (VLM).
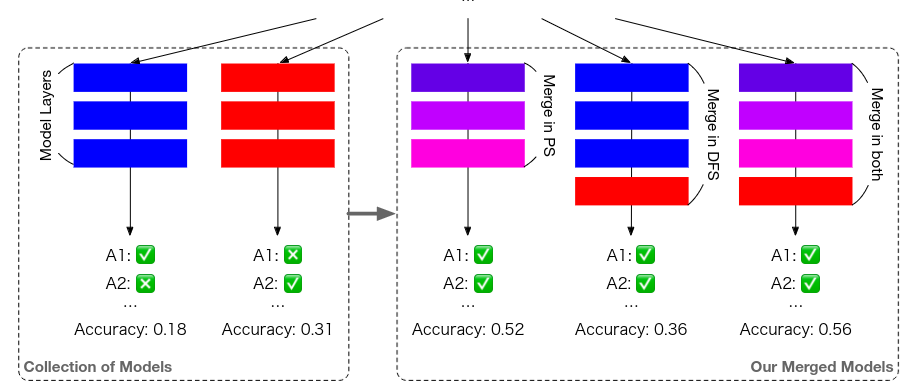
The way they train these models is with three different methods: the first one is by mixing parameters at each layer, the second one is by permuting layers on the stack and the third one is by using both methods at the same time. With these methods, they got amazing results.

They are not getting state of the art for their models against GPT-4. But they beat GPT-3.5 and are still consistently winning against models six times its size. This method beats expectations by a lot.
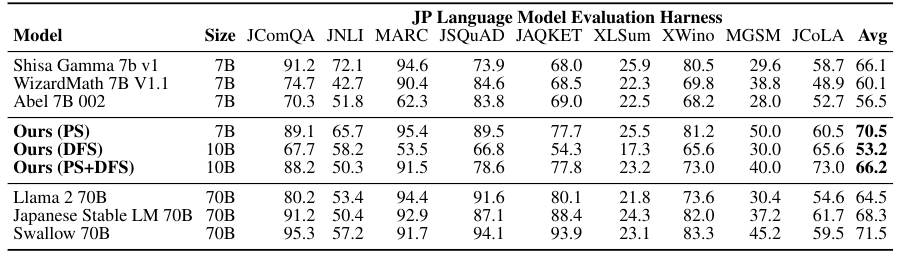
Because Sakana is a Japanese company, they really care about model performance in their language. They used the Japanese Language Proficiency Benchmark and got consistently State of the Art with really small models.
I would like to note that there is a lack of Mistral and Mixtral inclusions in all of these benchmarks. They do mention Mistral but I think they focus a lot more on the Japanese finetuning for the benchmarks.
I would like to speculate a little bit for the conclusion. They are going to use this method but with bigger models like Llama2 70B or Yi 34B. This method seems to work, and is scalable so we are going to see a model that is going to win against GPT-4. It is likely that within the next couple of months they will release this model.
If you would like to delve deeper into this subject, you can check out their release blog post here or the paper here.
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Researchers at Stanford and Notbad AI Inc have recently developed a new method for an AI model to think before they speak.
The new method is a generalization of the Self-Taught Reasoner (STaR) method. STaR works by “sampling rationales to attempt to answer questions”. The problem is that to use STaR you need curated QA datasets so they make a new generalizing method to not need a specific dataset and to make the AI model reason by itself.

The way that Quiet-STaR works is as follows. For every sentence that the model should generate they first generate a sequence of rationales. With these rationals they mix them using a “mixing head” that is a Multilayer Perceptron (MLP) and finally they optimize the rationales using REINFORCE to get a better result.
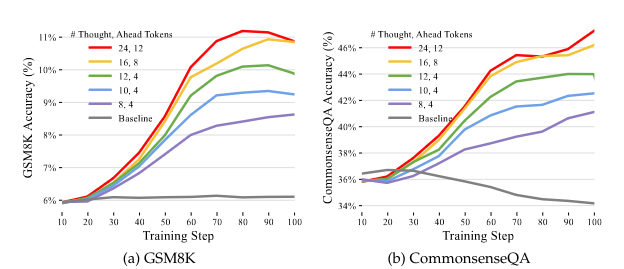
It seems that if you train a model to think, it works. They got better results in two really popular benchmarks named GSM8k and CommonsenseQA.
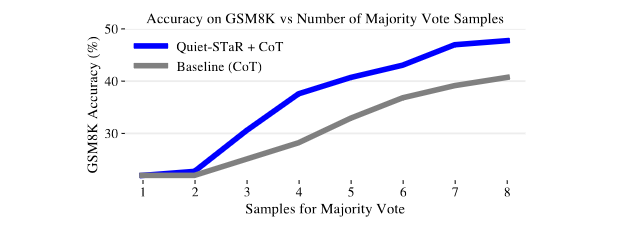
Finally, they outperformed by 20% the use of only Chain of Thought (CoT).
Yan Lecunn in an interview with Lex Friedman recently said that the problem with LLMs is that tokens cost the same for LLMs, they don’t have a method to have second level thinking. This shows that we can get some tokens to be more expensive than others and we can get a kind of second order thinking.
If you would like to read more, the paper is here.
GROK
Elon Musk has a personal beef with OpenAI. He thinks that the company should be more open. The problem is that xAI was not open either. Now, he has open sourced one of the biggest open source models, Grok. Grok is a 314 billion parameter mixture-of-expert model so it cannot be run at home (for now).
The model is not fine tuned for any particular task. If you try to talk to it, it might seem underwhelming, but remember that it lacks fine tuning for chatting. The release blog post is small, but at the same time it is interesting that they talked about the fact that they managed to have their entire tech stack since October.
xAI has still a long way to go to get to the top ranking members of the AI scene, but they seem to be at least more open than OpenAI. If you want to read the short post, it is here. If you would like to download the weights or see the code, it is here.
That’s it for this week! Thank you for reading, I hope that you have a nice weekend and rest of the week.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!