Welcome to Research Log #033! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
We talked last week in the Research Log #032 about how the team was on the final sprint with the Agent Survey. We want to congratulate the team for pushing this week and getting the v0 of the Agent Survey done! We are planning on releasing it shortly. If you are interested in joining the next steps of our research on agents you can check out the github or join the discord.
Pulse of AI
This week we have seen a lot of different model releases: the first production ready LLM that is based on State Space Machines, a new competitor to the biggest open source model that wins against Grok and a tiny model capable of punching up to the sky beating Claude-2.0 and Gemini Pro.
Jamba
AI21 Labs has been working on the first production ready State Space Machine (SSM) based model. This model has a new SSM Architecture named Jamba with a size of 52 billion parameters and a context window of 256k tokens.
The Mamba architecture offers an alternative to the Transformers. The best part about this State Space Machine architecture is that they remove the need for the Attention Mechanism. The attention mechanism is problematic because it is a matrix multiplication (an O(n²) operation). If you remove this part from the transformer, you have a massive speedup. But, removing the Attention mechanism generally leads to bad outputs.
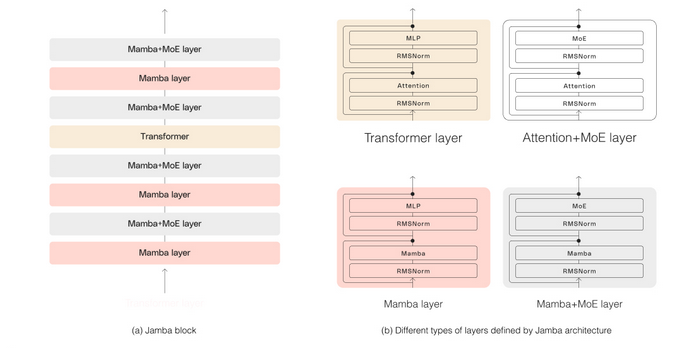
That is why the people at AI21 Labs have created a new architecture named Joint Attention and Mamba (Jamba). “Composed of Transformer, Mamba, and mixture-of-experts layers'”. The results speak for themselves.
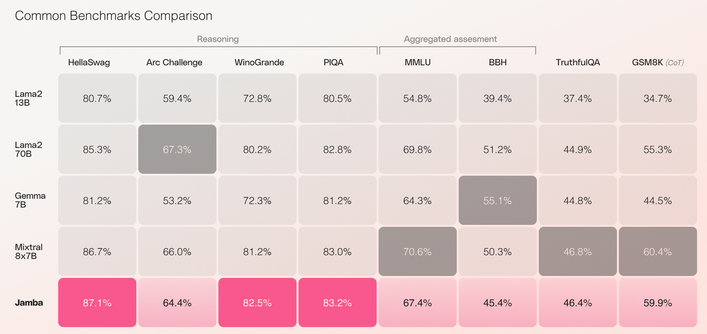
Jamba is 3x faster compared to Mixtral8x7b on long contexts and achieves state of the art results against comparable sized models in different benchmarks.
If you would like to test the model for yourself, the model is licensed Apache v2 and can be found here. And the original blog post for the release is here.
DBRX
Mosaic Research just released a new state of the art model. This model is a mixture-of-experts of 132 billion parameters and has a context length of 32k tokens.
DBRX makes several important decisions. First, the model has 16 experts under the hood and at any time it chooses 4 experts to generate the output. Then, they are using rotary position encodings (RoPE) and gated linear units (GLU). RoPE and GLU are becoming the norm for bigger models. Last but not least, they trained the model on 12 trillion tokens.
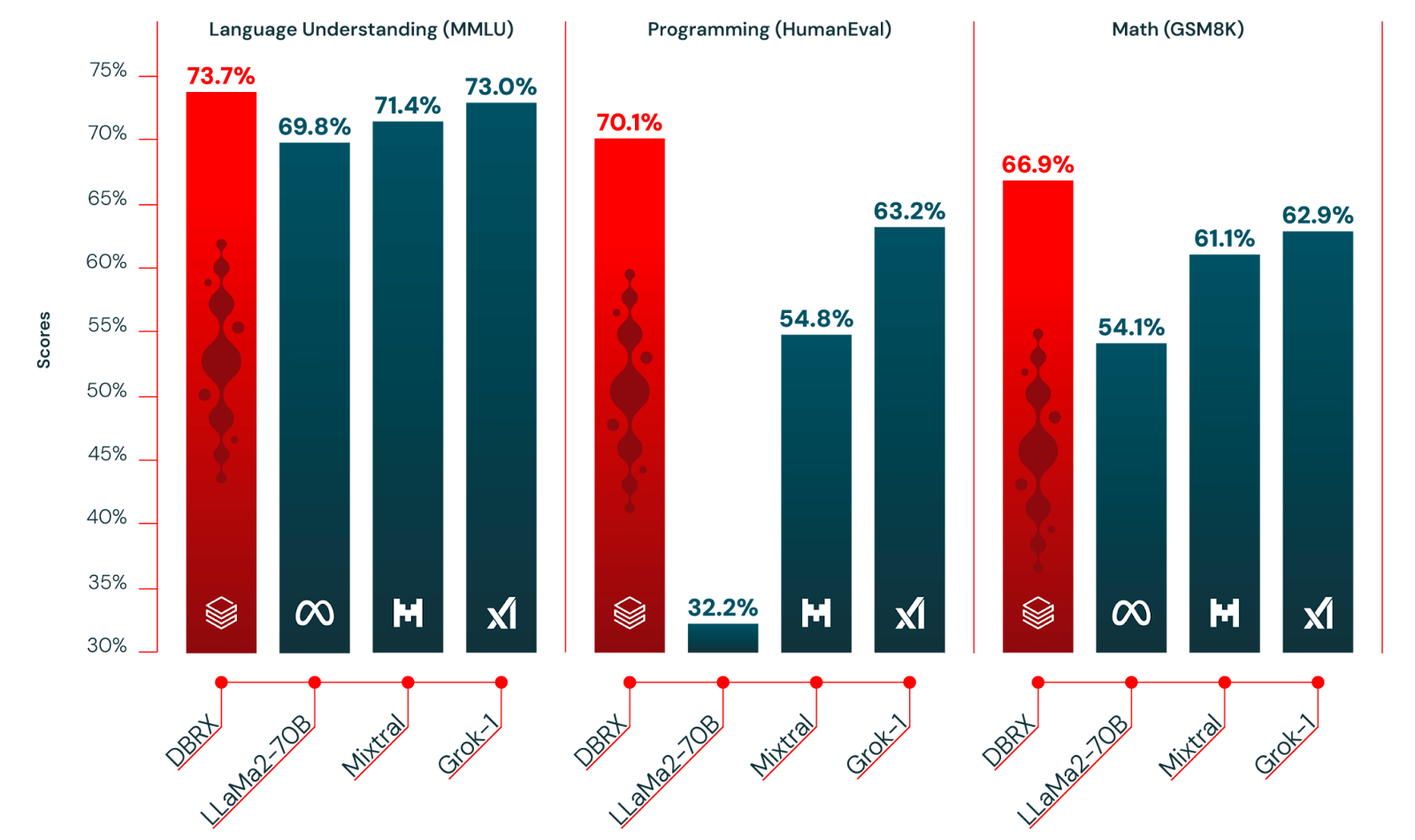
The model signals a trend happening in industry. People are starting to choose Open Source models because they can have control over it. DataBricks, the company behind Mosaic Research, partnered with NASDAQ, so that they don’t have to share data with any other company and they can self host.
The model is open source! But realistically nobody can run this model at home because it needs ~264 GB of RAM. The weights are here, the technical blog post is here and the release blog is here.
Starling-7B
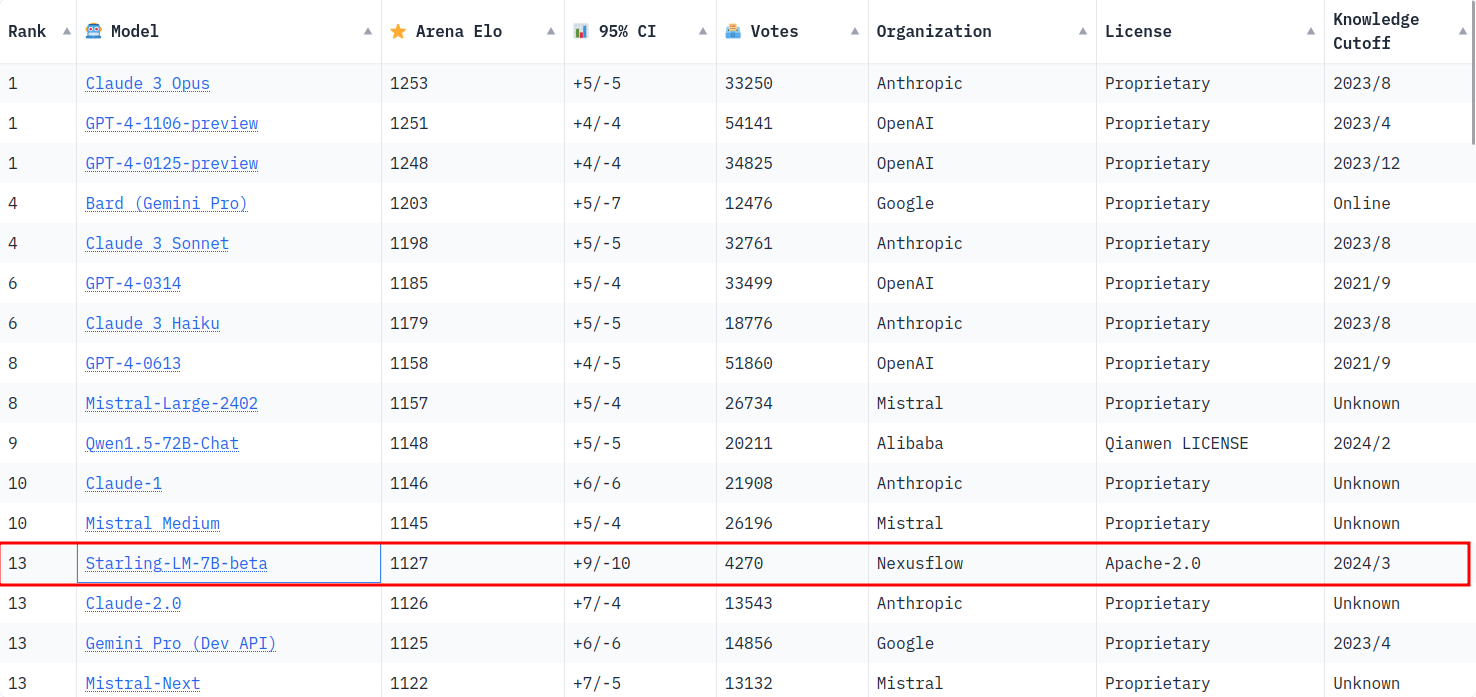
Researchers at Berkeley just released a tiny model in comparison to what we have been talking about this week. But it demonstrates that the training methodology and the datasets in Large Language Models can generate a really big difference. This 7B parameter model currently beats Claude-2.0, Gemini Pro and Mistral-Next on the LMSYS Chatbot Arena Leaderboard.
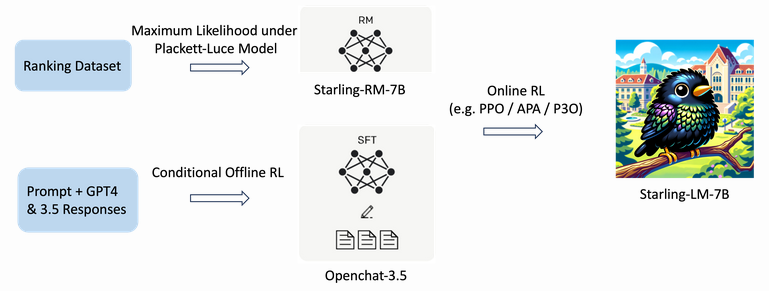
Starling-7B is a fine-tuned version of Openchat-3.5 using a new dataset named Nectar. Nectar is made out of a prompt and 7 different responses from different models. They finetuned the model with RLAIF by showing the model how GPT-4 ranked each answer so that he could learn what was the best answer.
If you would like to read more about how they managed to beat the biggest models in the industry right now, you can check out the release blog post here and the model is on huggingface here.
That’s all for now friends, thank you for reading.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!